Thanks to Michael Bryan, Mike McLaren, Simon Grimm, and many folks at the NAO for discussion that led to this tool and feedback on its implementation and UI.
The NAO works on identifying potential pandemics sooner, and most of our work so far has been on wastewater. In some ways wastewater is good—a single sample covers hundreds of thousands of people—but in other ways it’s not—sewage isn’t the ideal place to look for many kinds of viruses, especially respiratory ones.
We’ve been thinking a lot about other sample types, like nasal swabs, which have the opposite tradeoffs from wastewater: a single sample is just one person, but it’s a great place to look for respiratory viruses. But maybe then your constraint changes from whether you’re sequencing deeply enough to see the pathogen to whether you’re sampling enough people to include someone while they’re actively shedding the virus.
The interplay between these constraints was complicated enough that we decided to write a simulator, which then offered an opportunity to pull together a lot of other things we’ve been thinking about like the effect of delay, the short insert lengths you get with wastewater sequencing, cost estimates for different sequencing approaches, and the relative abundance of pathogens after controlling for incidence. We now have this in a form that seems worth sharing publicly: data.securebio.org/simulator.
The simulation is only as good as its inputs, and some of the inputs are pretty rough, but here’s an example. Let’s say we’re willing to spend ~$1M/y on a detection system looking for blatantly genetically engineered variants of any known human-infecting RNA virus. We’re considering two approaches:
Very deep weekly short-read wastewater sequencing. The main cost is the sequencing.
Shallower daily long-read nasal swab sequencing. The main cost is collecting the nasal swabs.
We’d like to know how many people would be infected (“cumulative incidence”) before the system can raise the alarm.
If the virus happens to shed somewhat like SARS-CoV-2, here’s what the simulator gives us:
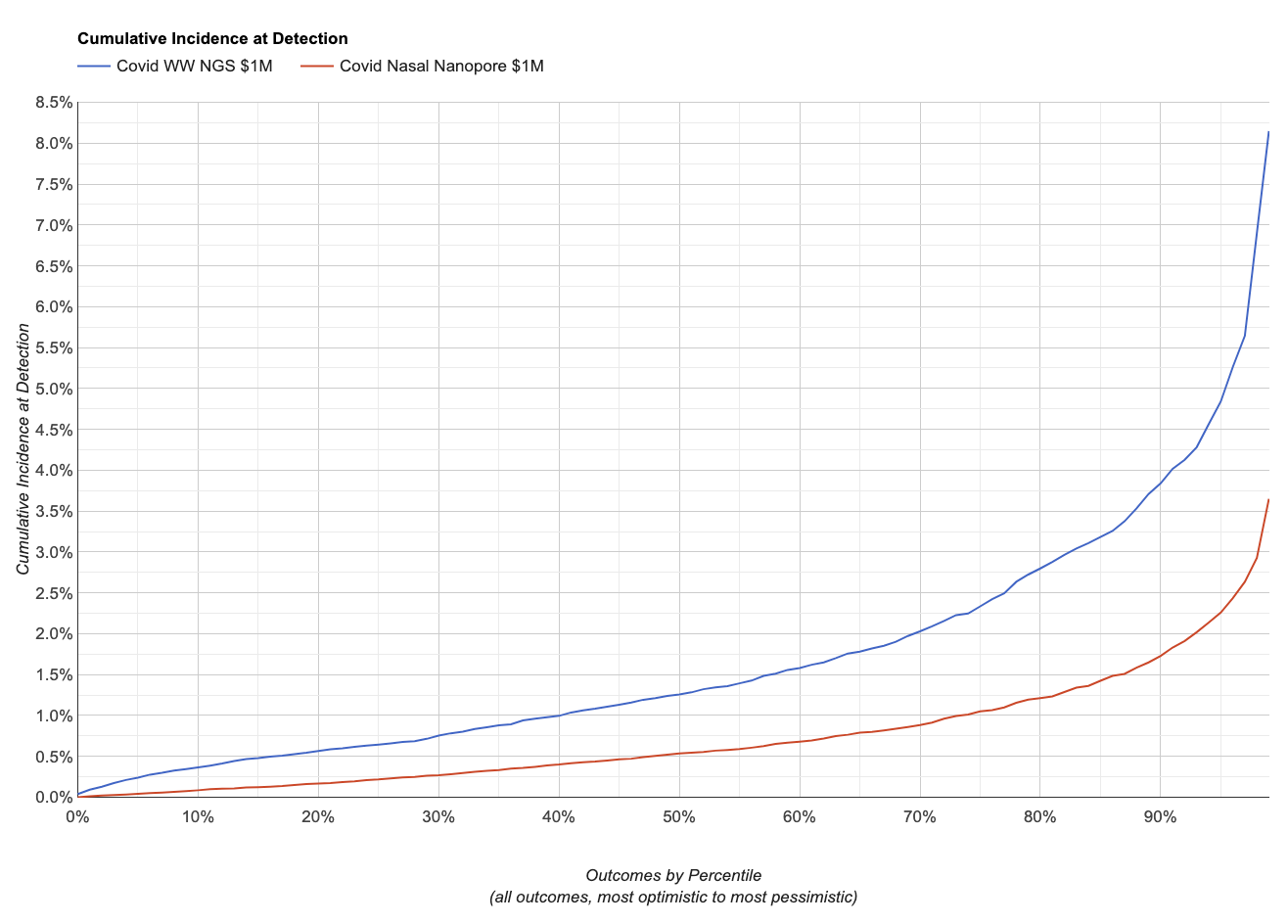
A higher cumulative incidence at detection means more people have been infected, so on this chart lower is better. Given the inputs we used, the simulator projects Nanopore sequencing on nasal swabs would have about twice the sensitivity as Illumina sequecing on wastewater. It also projects that the difference is larger at the low percentiles: when sequencing swabs there’s a chance someone you swab early on has it, while with wastewater’s far larger per-sample population early cases will likely be lost through dilution. You can explore this scenario and see the specific parameter settings here.
Instead, if it sheds like influenza, which we estimate is ~4x less abundant in wastewater for a given incidence, it gives:
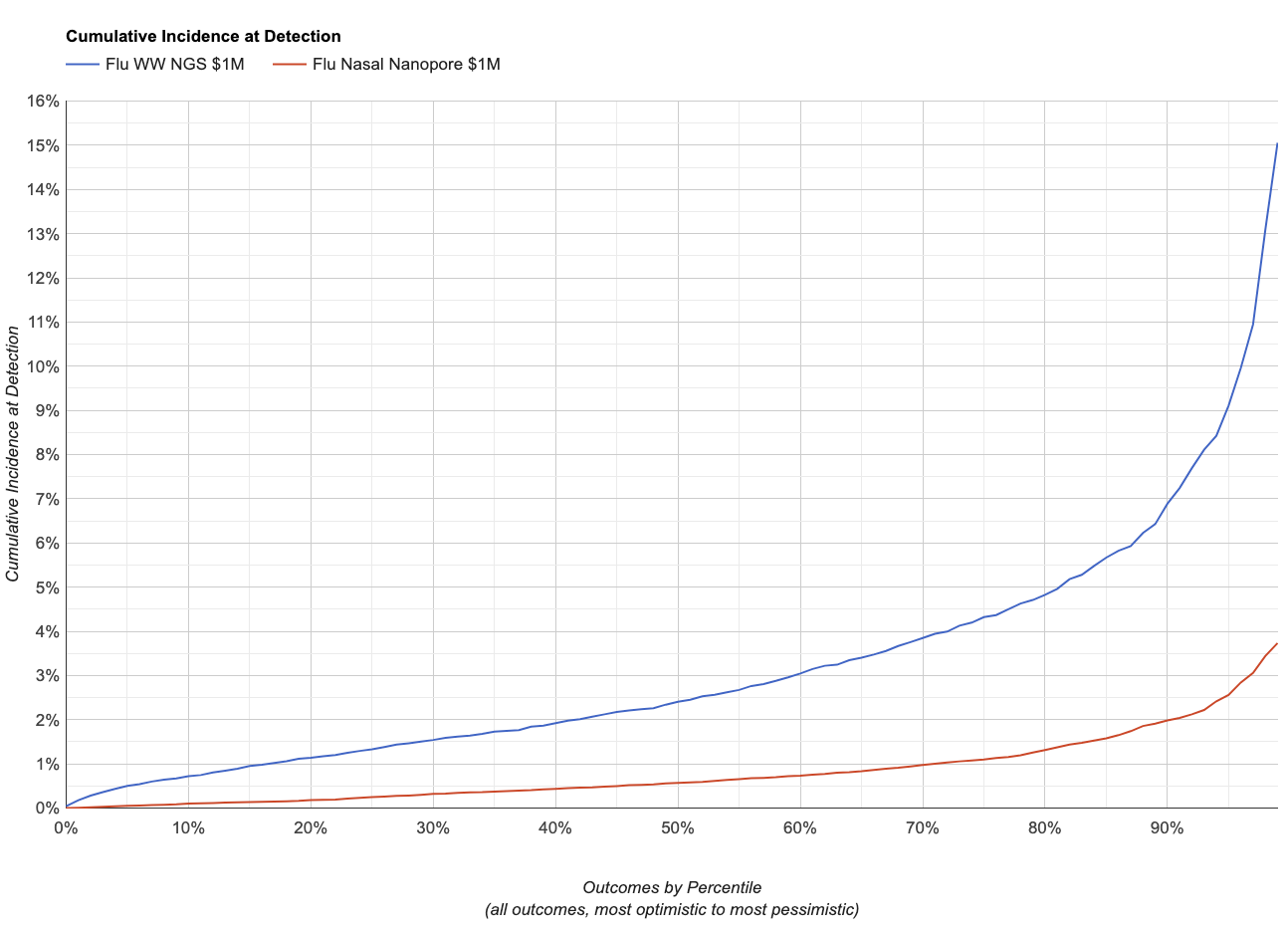
This makes sense: if the pathogen sheds less in wastewater the system will be less sensitive for a given amount of sequencing.
On one hand, please don’t take the simulator results too seriously: there are a lot of inputs we only know to an order of magnitude, and there are major ways it could be wrong. On the other hand, however, Jeff adds that it does represent his current best guesses on all the parameters, and he does rely on the output heavily in prioritizing his work.1
If you see any weird results when playing with it, let us know! Whether they’re bugs or just non-intuitive outputs, that’s interesting either way.
Footnotes
Since writing Sequencing Swabs and especially in the last month Jeff has been working on spinning up a swab sampling effort. Initially he was thinking we’d probably partner with an existing organization that has done something similar, but after talking to a couple decided it was worth trying it ourselves to see if we can do it more cheaply. We’re in the process of getting IRB and biosafety approval, and the soonest this sampling might start is early May.↩︎